


Artificial intelligence is based on the idea of formalizing human thinking and executing it by machine. The basics come from various areas of knowledge and some were created several hundred years ago. The term was coined by the programmer John McCarthy at a workshop that, among other things, dealt with the machine simulation of neural networks. They emerged from a combination of threshold elements – the neurons – which the cyberneticist Warren McCulloch and the logician Walter Pitts had previously introduced into computer science as abstract models of human neurons.
Basic principles of self-developed neural networks
However, slow computers and a laborious manual method for training neural networks caused the research area to stagnate. David Rumelhart and his colleagues solved the learning problem in 1986 with their back-propagation algorithm, which enables machine learning in an amazingly simple way. However, the topic only really took off around 2010, when the AI community discovered the power of modern graphics chips for their purposes. Since then, new and more powerful types of neural networks have been replacing each other at an ever-increasing rate. The current highlight is the so-called Transformer, a generative neural network and the state of the art, which is also the basis for ChatGPT, for example. In 2016, the Asimov Institute attempted to create a complete overview of the network types discussed at the time, “mostly complete”, as they themselves said, and published an illustrative poster about it.
- AI apps almost exclusively use neural networks.
- A simple network for handwriting recognition can be programmed with just a little code.
- Neural networks must be trained; in the example presented, this is done with scanned digits.

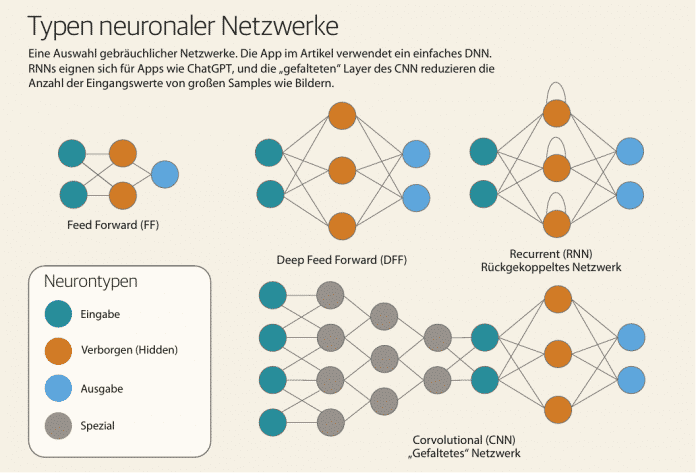
From a distance, almost all types of neural networks work on the same principle, which distinguishes between two operating modes: applying the network to an input value (prediction) and learning it (training). During prediction, the network provides a value for the probability with which the result matches an expected value (target). During training, the network compares the values of predictions with the corresponding targets and adjusts its internal configuration based on the differences.
