


Nvidia Research's Toronto AI Lab has introduced the Large-scale Amortized Text-To-Enhanced3D Synthesis (LATTE3D) research project, an AI model for generating textured 3D objects from text prompts. Nvidia promises that LATTE3D can convert text descriptions into three-dimensional objects better and faster than comparable approaches.
Advertisement

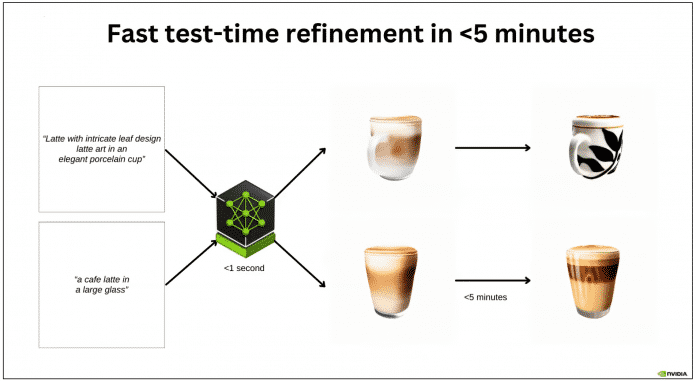
According to Nvidia Research, LATTE3D creates textured 3D objects on an A6000 GPU in under a second, but the model requires several minutes for more details.
(Image: Nvidia)
According to the research, the core of LATTE3D is a text-based 3D rendering process that takes a text description and delivers a complete 3D object. The process is divided into two main phases: the initial volumetric rendering to train the texture and geometry of the object, and the subsequent surface rendering to improve the texture quality. In this way, high-quality 3D assets can be created in just 400 milliseconds, the researchers write in their paper.
technical basics
LATTE3D uses two specialized networks: a texture network and a geometry network, which is based on a combination of Triplanes (mapping 3D structures by projecting them onto three orthogonal planes) and U-Nets (Convolutional Neural Networks for image segmentation). Initially, the encoders of both networks share the same weights, while in a later phase the geometry network is frozen and the texture network is updated. According to Nvidia, the efficiency of the Triplanes is increased by a multi-layer perceptron (MLP) that uses text embeddings as input.
LATTE3D was trained on 100,000 text inputs generated by augmenting image captions of the LVIS-Objaverse subset using ChatGPT. According to Nvidia Research, the system shows strong generalization ability for both new labels extended in the distribution and for unknown prompts outside the distribution.
Compared to other text-to-3D generators such as MVDream, 3DTopia, LGM and ATT3D, LATTE3D is said to be superior in terms of speed and quality of 3D object generation. The results are generated in real time on an A6000 GPU, with up to four samples possible for each prompt, according to Nvidia.
The possible uses of such text-to-3D generators range from quickly designing entire scenes to iterating object designs. So far, however, there is only LATTE3D's research work and demo videos; you cannot currently try out the text-to-3D generator.
(v.a.z.a.)
