


In order to be able to measure the benefits of the individual Large Language Models (LLM) for cybersecurity, researchers at the security company Sophos have developed criteria for the comparability of such models. To do this, they created benchmark tasks, i.e. typical problems that can be used to quickly and easily assess the capabilities of a model. The models were selected based on criteria such as model size, popularity, context size and topicality. Different sized versions of the Llama 2 and Code Llama models from Meta, Amazon's Titan Large and GPT-4 were tested.
Advertisement
The tasks consisted of three scenarios. In the first, the LLM was intended to act as an assistant in the investigation of security incidents. To do this, it should retrieve relevant telemetry information based on natural language queries. The ability to convert these queries into SQL statements was assessed.
Summarize and evaluate incidents
In the second scenario, the LLM should generate incident summaries from data from a Security Operations Center (SOC). The background is the large volume of events that occur in networks and user endpoints related to suspicious operations. For SOC analysts, they are the starting point for further investigation into whether there is actually a security incident. Since the sequences of events are often confusing, language models can provide support by identifying and organizing the event data. On this basis, the analysts can plan their next steps.


Following this template, LLMs should submit the data for the event summary benchmark.
(Image: Sophos)
In the third scenario, the LLM had to assess the severity of the incident, which corresponds to a modified version of the classic ML problem in IT security: Is an observed phenomenon harmless or part of an attack? To do this, Sophos used a data set of 310 incidents from its MDR-SOC (Managed Detection and Response), each formatted as a series of JSON events with different schemas and attributes depending on the sensor collecting them. This data was passed to the model along with instructions for summarizing the data and a predefined template for the summarization process.
Leaders GPT-4 and Claude v2
Although the benchmark test cannot take into account all potential problems, the researchers concluded, LLMs can be an effective support in the investigation of security incidents and can be used as assistants – but this requires further guidelines and instructions.
Most LLMs perform adequately at summarizing incident information from raw data, although there is still room for improvement through fine-tuning. In particular, the evaluation of individual artifacts or groups of artifacts is a challenging task for already trained publicly available LLMs. Addressing this issue may require a specialized LLM trained in cybersecurity data.
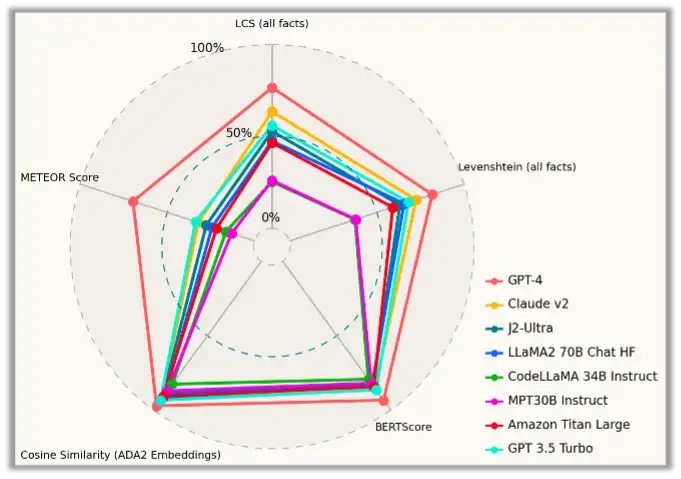
When summarizing the incidents (task 2), all LLMs performed adequately. However, GPT-4's advantage is quite clear.
(Image: Sophos)
In terms of pure performance, GPT-4 and Claude v2 performed best in all benchmarks. In the first task, the CodeLlama-34B model also received an honorable mention for its good performance. According to the researchers, it is a competitive model for use as a SOC assistant.
Further details and evaluations of the various tasks can be found in the English blog post from Sophos.
(ur)
