


The new version 1.5 or 1.5.1 of the royalty-free audio codec Opus has received an AI update. Machine learning (ML) is intended to improve the encoding so that the data stream remains compatible with existing decoders. But the decoder also receives artificial intelligence to improve the sound.
Advertisement
The developers write that Opus has already received the optimized distinction between speech and music using machine learning. With the current update, however, he received deep learning techniques to process or generate the signals themselves.
Opus codec: Bitstream remains standard compatible
Opus remains fully compatible instead of programming a new ML-based codec from scratch. This ensures that Opus continues to run on older and slower devices, but still provides an easy upgrade path. While deep learning is often linked to powerful GPU accelerators, the Opus project has optimized everything to run on most processors, including smartphone CPUs.
Most users shouldn't notice a higher load, but those using microprocessors or smartphones that are more than five years old may notice it. The new functions are therefore still deactivated by default; they must be activated during compilation and also at runtime using command line parameters.
Improvements in packet loss
Packet losses result in missing snippets of sound. Codecs usually try to prevent this through packet loss concealment (PLC). This is usually a type of decoder-side interpolation with “plausible audio” that is included in the loss points. Machine learning could be particularly helpful here – the Opus developers are approaching this with a Deep Neural Network (DNN), which increases the binary file of the codec by around 1 MB and leads to one percent more load on a laptop CPU core in the event of severe packet losses .
Deep Redundancy (DRED) is intended to transmit packets with redundancy data for one second in addition to the typically 20ms second audio packets with only 12-32 kbit/s overhead. Here too, ML enables high compression, which should lead to significantly better output.
AI for better sound quality
A technique called “Neural Vocoder” is intended to compress speech particularly efficiently. Compared to the LPCNet Vocoder, the load on laptop or smartphone CPU cores should only be around one percent. The developers call the algorithm Framewise AutoRegressive Generative Adversarial Network (FARGAN). You want to publish a paper on this at a later date.
They optimize signal processing with Linear Adaptive Coding Enhancer (LACE) and a non-linear variant (NoLACE). LACE behaves like a classic post-filter, in which a deep neural network (DNN) adjusts the coefficients with all available data during operation – but the audio signal does not pass through the DNN. This results in a small DNN with very low complexity that can also run on older phones. The NoLACE variation requires more computing power, but is also significantly more powerful due to non-linear signal processing. Both significantly improve voice quality.

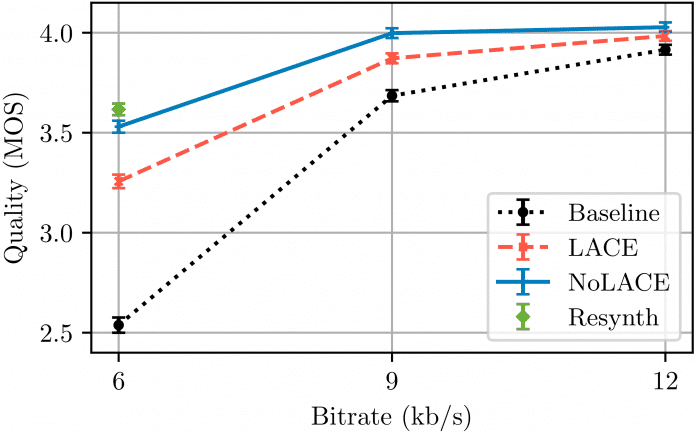
Subjective Hearing Tests (MOS) compare speech quality using the standard decoder with the encoded data streams enhanced by LACE and NoLACE. LACE is usable from 6 kbit/s, while NoLACE achieves almost transparency at 9 kbit/s, the developers explain.
(Image: Opus)
For further development, the Opus developers write that they are working in the IETF's newly founded mlcodec group to ensure compatibility with the existing and future Opus. For DRED, for example, additional information is required in Opus packages, which an old decoder must still be able to process. This can be achieved using the padding mechanism.
Further optimizations include support for SIMD processor instruction extensions. This is how DNN code and SILK encoders run faster with AVX2/FMA. In particular, NEON optimizations accelerate Opus' DNN on ARM CPUs (AArch64). On the same day of the release of Opus 1.5, the developers followed up with libopus 1.5.1, which fixes the broken build process with Meson.
Standard for twelve years
The Opus audio codec was cast into the RFC standard 6716 in 2012 and can be used without license fees. It stands out with its low latencies and a wide range of applications from VoIP (e.g. mono audio for web telephony and conferences) to musical multitrack recordings with high bit rates. It emerged from Skype's SILK voice compression codec and CELT (Constrained-Energy Lapped Transform) audio compressor invented by Xiph founder Christopher Montgomery. The codec enjoys widespread support as developers are allowed to use it free of charge.
In addition to Opus, Cisco's Webex codecs have received new AI functions that, in addition to automatic transcription, also promise sound improvements. The AI is intended to block out background noise and provide improved speaker focus. There is also a pure AI audio codec, which should only work with a 16th of the Opus bit rate even with low bandwidth and packet losses. Microsoft has been using AI-optimized audio codecs in Teams for three years, which, like Opus, should deliver suitable results from 6 kbit/s. However, they are not intended to provide any advantages in terms of latency.
(dmk)
